AI is the branch of Computer Science that deals with the creation of intelligent systems (machines + software) that are capable of performing tasks like reasoning, learning, problem solving, perception, and language understanding. Thus, AI deals with the theory and methods to build machines that think and act like humans.
Generative AI is a type of artificial intelligence technology that produces various types of content like text, image, audio, video, code and synthetic data.
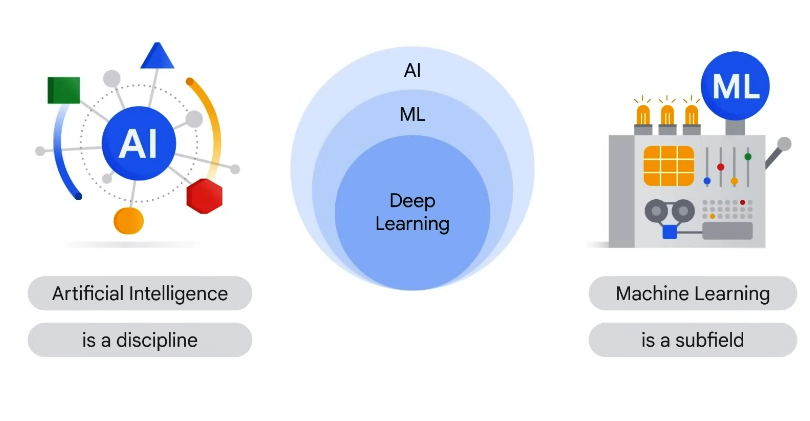
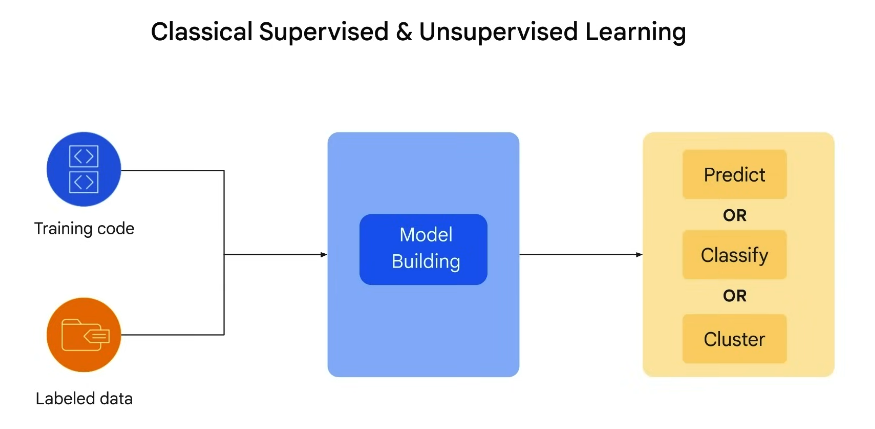
Machine Learning is a subset of AI. It is a program or system that trains a model from input data. The trained model can make useful predictions from the new data (not used earlier) drawn from the same data set used to train the model. Thus, ML enables the computer to learn without explicit programming.
Types of ML
1. Supervised ML
2. Unsupervised ML
3. Reinforcement ML
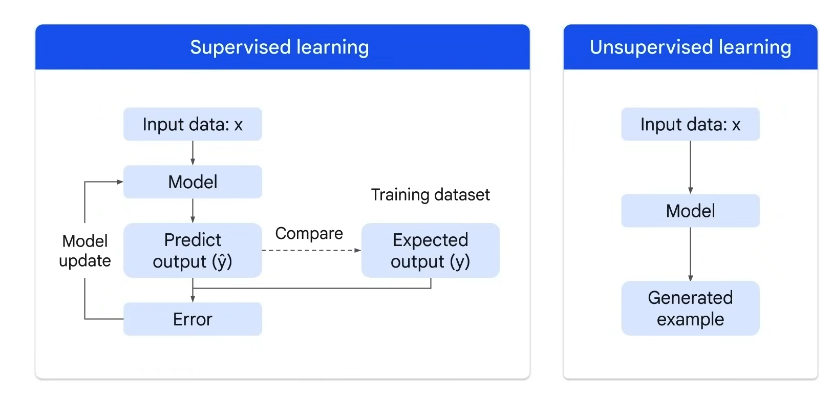
(1) Supervised ML Models use labeled data. Labeled Data is a data that comes with a tag like a name, a type or a number. In supervised learning, the machines are learning from past examples to predict the future values. An example of supervised learning is the classification of emails into spam or non-spam categories. The algorithm learns from labelled data, distinguishing between the two categories based on features such as keywords and sender information.
(2) Unsupervised ML Models use unlabeled data. Unlabeled data comes with no tag. It tries to identify hidden patterns, structures, relationships or groups within the dataset without explicit guidance. The three primary types of unsupervised learning are clustering, association and dimensionality reduction. Clustering involves grouping similar data points, while association aims to discover relationships and dependencies between variables in a dataset. Unsupervised learning is employed to analyse and categorize social media posts, tweets, or comments into topics or sentiments. This helps businesses understand public opinions and trends. Google News by clustering news articles into topics using unsupervised learning for personalized content delivery is another example of Unsupervised learning.
Supervised Learning Vs Unsupervised Learning
Differences: Supervised ML Vs Unsupervised ML
| Description | Supervised Learning | Unsupervised learning |
| Definition | Supervised learning algorithms train data, where every input has a corresponding output. | Unsupervised learning algorithms find patterns in data that has no predefined labels. |
| Objective | To approximate a function that maps inputs to outputs. | To build a concise representation of the data and generate imaginative content from it. |
| Goal | Predict outcomes or classifies data based on known input labels. | Discovers hidden patterns, structures, or groupings or relationships in data. |
| Accuracy | Highly accurate and reliable. | Less accurate and reliable. |
| Complexity | Less complex, as the model learns from labeled data with clear guidance. | More complex, as the model must find patterns without any guidance. |
| Classes | Number of classes is known. | Number of classes is unknown. |
| Input | Labelled data. | Unlabeled raw data. |
| Output | Pre-defined output value. | No corresponding output values. |
| Types | Classification &Regression for discrete and continuous outputs respectively. | Clustering, Association and Dimensionality Reduction. |
| Model Testing | Model can be tested and evaluated using labeled test data. | Cannot be tested as there are no labels. |
| Human Supervision | Algorithm needs human supervision to train the model. | Algorithm does not need any kind of human supervision to train the model. |
| Algorithms Use | Linear regression, K-Nearest Neighbors, Decision Trees, Naive Bayes, SVM | K-Means Clustering, DBSCAN, Autoencoders. |
| Uses | Image classification, Sentiment Analysis, Recommendation systems | Customer Segmentation, Anomaly Detection, NLP, Recommendation Engines. |
Clustering Method for Unsupervised ML
Clustering methods involve grouping untagged data based on their similarities and differences. When two instances appear in different groups, we can infer they have dissimilar properties. Clustering is a popular type of unsupervised learning approach. The different types of clustering are:
Exclusive clustering: Data is grouped such that a single data point exclusively belongs to one cluster.
Overlapping clustering: A soft cluster in which a single data point may belong to multiple clusters with varying degrees of membership.
Hierarchical clustering: A type of clustering in which groups are created so that similar instances are within the same group and different objects are in other groups.
Probabilistic clustering: Clusters are created using probability distribution.
Association Rule Method for Unsupervised ML
This type of unsupervised machine learning takes a rule-based approach to discovering relationships in a given dataset. It tries to identify strong rules within a dataset. Example: association rule mining technique is used by retailers to gain a better understanding of customer purchasing patterns based on the relationships between various products.
One of the most widely used algorithms for association rule learning is the Apriori algorithm. However, other algorithms are also used for this type of unsupervised learning, such as the Eclat and FP-growth algorithms.
Dimensionality ReductionMethod for Unsupervised ML
Dimensionality Reduction is the process of reducing the number of input variables or features in a data set while retaining the key features. Popular algorithms used for dimensionality reduction include Principal Component Analysis (PCA) and Singular Value Decomposition (SVD). These algorithms seek to transform data from high-dimensional spaces to low-dimensional spaces without compromising meaningful properties in the original data. These techniques are typically deployed during exploratory data analysis (EDA) or data processing to prepare the data for modeling.
It’s helpful to reduce the dimensionality of a dataset during EDA to help visualize data: this is because 3D visualization of data is difficult. From a data processing perspective, reducing the dimensionality of the data simplifies the modeling problem.
When more input features are being fed into the model, the model must learn a more complex approximation function. This phenomenon can be summed up by a saying called the “curse of dimensionality.”
(3)Reinforcement Learning (RL)
It is a ML technique that trains software to make decisions to achieve the optimum results. It mimics the trial-and-error learning process that humans use to achieve their goals. Software actions that work towards the goal are reinforced, while actions that detract from the goal are ignored.
In Model-Based Reinforcement Learning, an agent uses a model to create additional experiences while in Model-Free Reinforcement Learning, the agent directly interacts with the environment and tries different scenarios and tests whether they’re successful.
In reinforcement learning, there are a few key components :
- Agent – The ML algorithm or the autonomous system.
- Environment – It is the adaptive problem space with attributes such as variables, boundary values, rules and valid actions
- Action – The steps that the RL agent takes to navigate the environment to reach the goal.
- State – The environment at a given point in time
- Reward – It is the positive, negative, or zero value – in other words, the reward or punishment -for taking an action.
- Cumulative reward- It is the sum of all rewards or the end value.
Deep Learning
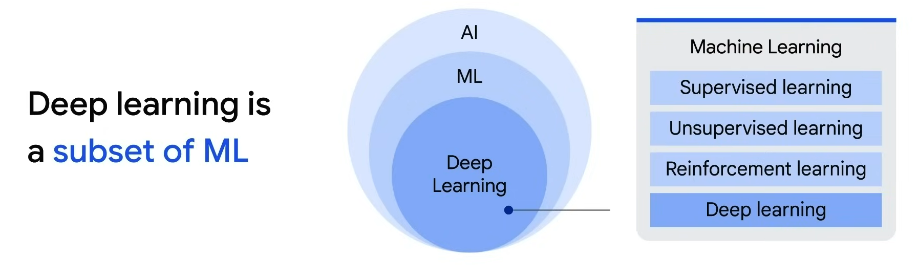
Deep Learning is a subset of ML It Uses artificial neural networks to process more complex patterns than machine learning. Like our brain, they are made up of many interconnected nodes or neurons that can learn to perform tasks by processing data and making predictions. In semi-supervised learning, a neural network is trained on a small set of labeled data and a large set of unlabeled data. The labeled data helps the neural network to learn the basic concepts while the unlabeled data helps the neural network to generate the new example. Generative AI is a subset of Deep Learning by using Artificial Neural Networks. It can process both labeled and unlabeled data using supervised, semi-supervised and unsupervised methods.
Large Language Models are also a subset of Deep Learning.
Types of Deep Learning Models
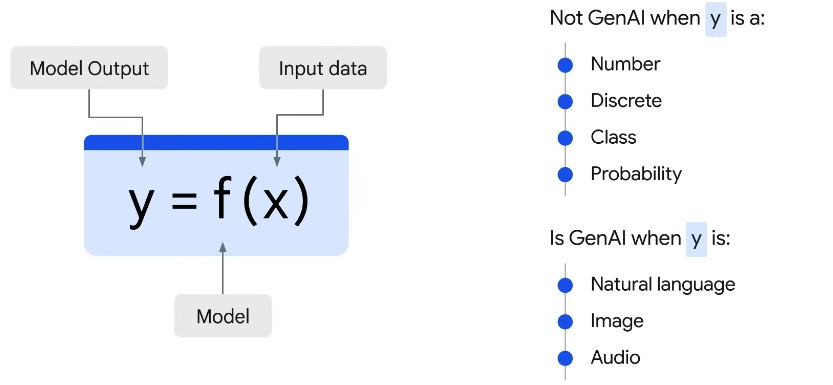
Discriminative Model: It is used to classify or predict labels for data points. They are trained on a dataset of labeled data points and learn the relationship between the features of data points and the labels. Discriminate Model is used to predict the label for new data point.
Generative Model: It generates new data instances based on a learned probability distribution of existing data. Let x be our input, y be our output. Let x be the image of dog. Then, Generative Model learns the joint probablity distribution p(x,y) and predicts the conditional probability that this a dog and then produces a new picture of a dog . In Generative AI, the output is always a Natural Language like speech or text, Audio or Image. It is a new content.
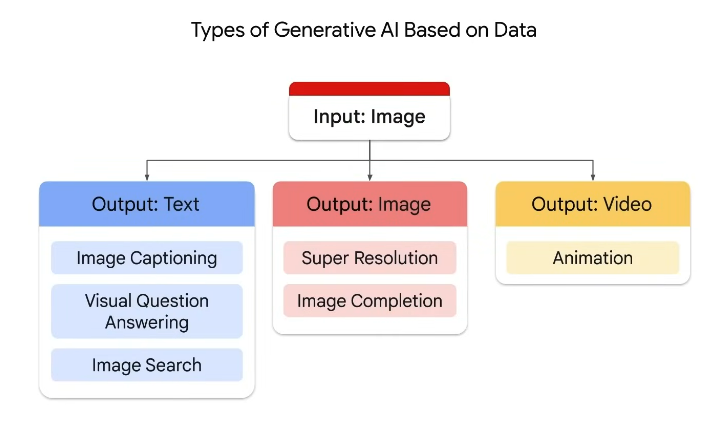


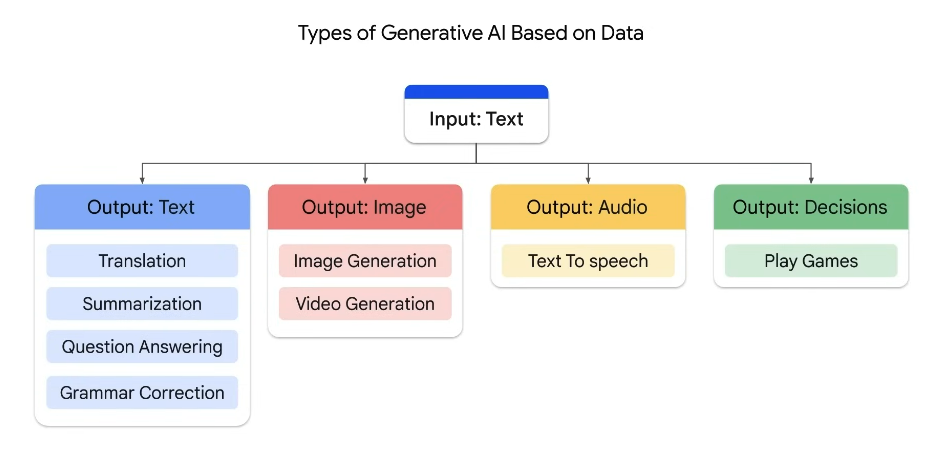

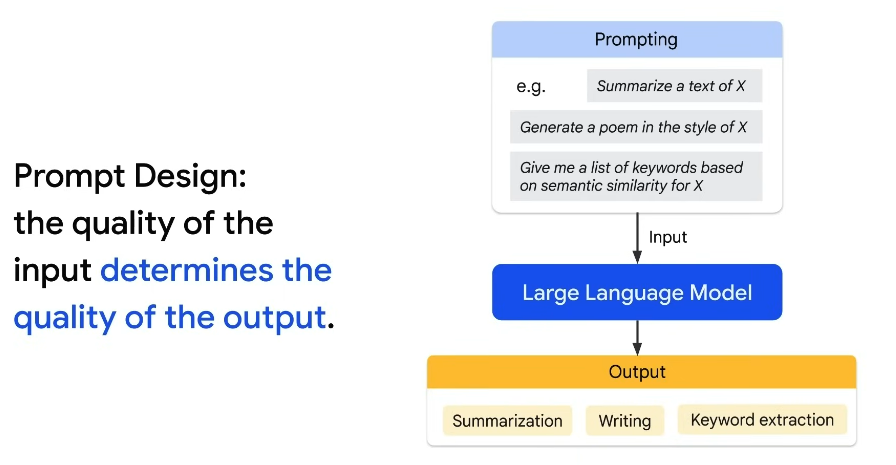
Prompt Design is the process of creating a prompt that generates the desired output from LLM.
Prompt Model Types: Used to train Gen AI.




Types of Machine Learning Algorithms
1. Supervised Learning Algorithms-Learn from labeled data.
| Algorithm | Description | Application |
| Linear Regression | Predict numeric values. | Predict housing prices |
| Logistic Regression | Predict categories. | Email spam detection |
| Polynomial Regression | Extends linear regression with polynomial features. | Sales, Climate Modeling, Thermodynamic processes |
| Ridge Regression (L2 Regularization) | Adds L2 penalty to prevent overfitting. Model stability and handles multicollinearity. | Stock return, Sales, Sentiment analysis |
| Lasso Regression (L1 Regularization) | Adds L1 penalty for feature selection. | Disease prediction, NLP, Stock prediction |
| Elastic Net Regression | Combines L1 and L2 penalties. Prevents overfitting. | Genomics, E Commerce, Finance |
| Linear Discriminant Analysis (LDA) | Projects data to maximize Classification (main use) and Dimensionality reduction (secondary use) | Medical diagnosis, Facial recognition |
| Quadratic Discriminant Analysis (QDA) | Bayesian principles, giving probabilistic outputs with curved or elliptical decision boundaries. | Medical diagnosis, Anomaly detection |
| Rule-Based Classifiers- RIPPER Repeated Incremental Pruning to Produce Error Reduction | Rule based output from noisy data. | Medical diagnosis, Fraud detection, Legal & compliance, Spam |
| Decision Trees | Rule-based decisions | Customer churn prediction |
| Random Forest | Ensemble of trees for better accuracy. | Fraud detection |
| Support Vector Machines (SVM) | Classification with a decision boundary. | Face recognition |
| K-Nearest Neighbors (KNN) | Classify based on closest data points. | Handwriting recognition |
| Naive Bayes | Probability-based classification. Extremely fast. | Sentiment analysis, Medical diagnosis |
| Gradient Boosting | Strong predictions from weak models. One of the most accurate ML techniques. | Loan default prediction, Web & Tech, Risk Modeling |
| Adaptive Boosting | Strong predictions from weak models. | Disease diagnosis, Credit scoring, Face detection |
2. Unsupervised Learning Algorithms– Learn from unlabeled data to find hidden patterns or structure.
| Algorithm | Description | Application |
| K-Means Clustering | Group similar data points | Customer segmentation |
| Hierarchical Clustering Agglomerative (Bottom-up approach) Divisive (Top-down approach) | Builds a tree-like structure (dendrogram) of clusters. | Gene classification, Psychology & Social Sciences |
| Principal Component Analysis (PCA) | Dimensionality reduction. Simplify complex datasets. | NLP, Image compression, Genomics |
| Autoencoders | Learn efficient data encoding. Handles complex, non-linear transformations. | Anomaly detection, Speech processing |
| DBSCAN (Density-Based Spatial Clustering) | Finds clusters based on density. Classifies Core Point, Border Point, Noise Point | Geospatial Analysis, Customer Behaviour |
| Gaussian Mixture Models (GMM) | To generate data from multiple Gaussian distributions. | Brain imaging, Genomics |
| Mean-Shift Clustering | To discover clusters by shifting points towards mode. | Geospatial Analysis, |
| Spectral Clustering | To Use graph theory to cluster based on eigenvalues. | Social Network analysis |
| t-SNE (t-Distributed Stochastic Neighbor Embedding) | Dimensionality reduction. Visualizes high-dimensional data in 2D/3D. | Non-linear Data Visualisation |
| UMAP (Uniform Manifold Approximation and Projection) | Dimensionality reduction .More efficient alternative to t-SNE. | Genomics |
| Autoencoders | Dimensionality reduction, denoising, unsupervised learning | Anomaly detection, Image compression, Data visualization |
| Apriori Algorithm | Association Rule Mining. Finds frequent item sets. | Fraud detection |
| FP-Growth (Frequent Pattern Growth) | Association Rule Mining. Faster than Apriori, Uses a tree structure. | Web Usage Mining and Fraud Detection |
| Eclat Algorithm | Association Rule Mining. Uses vertical data format for frequent itemset mining. | Web usage mining, Market basket analysis |
| Isolation Forest | Detect anomalies by using random forests. | Data cleansing, Network security |
| One-Class SVM | Trains on “normal” data to detect deviations. | Fault detection, Novelty detection |
| Local Outlier Factor (LOF) | Measures local density deviation. | Local anomaly |
3. Reinforcement Learning Algorithms- Theagent learns by interacting with an environment, receiving rewards or penalties for its actions and optimizing its strategy to maximize cumulative rewards.
(a)Value Based-They learn a value function-a measure of goodness in performing the task.
| Algorithm | Description | Application |
| Q-Learning | Learn actions to maximize reward | Chess |
| Deep Q-Networks (DQN) | Neural network version of Q-learning | Robot control, DeepMind Games |
| SARSA (State-Action-Reward-State-Action) | Similar to Q-Learning, but learns the value of the policy it is currently following. | Grid world navigation |
(b)Policy-Based Algorithms-Learn a policy directly (mapping from states to actions) without needing a value function.
| Algorithm | Description | Application |
| REINFORCE | Monte Carlo policy gradient method. Updates the policy based on complete episodes. | Robot path planning |
| Policy Gradient (PG) | Learns parameters of a stochastic policy using gradients. Optimize decisions directly | Robotic arm control, Stock trading bots |
| Actor-Critic | Combines policy-based and value-based methods (Actor updates the policy, Critic estimates value). | Real-time decision making |
(c) Model-Based Algorithms-These build a model and use it for learning and planning.
| Algorithm | Description | Application |
| Dyna-Q | Integrates Q-learning with a model for planning. | Simulated agents in games |
| Monte Carlo Tree Search (MCTS) | Uses simulations to build a tree of possible actions. | AlphaGo game-playing |
| MBRL (Model-Based RL with Neural Networks) | Learns environment dynamics. | Robotics |
(d) Inverse Reinforcement Learning (IRL) Algorithms-Learns reward functions from expert demonstrations.
| Algorithm | Description | Application |
| GAIL (Generative Adversarial Imitation Learning) | Used in imitation learning. | Robotics, Autonomous driving |
(e) Advanced Deep Reinforcement Learning Algorithms- Combine neural networks with RL for solving complex tasks with high-dimensional data.
| Algorithm | Description | Application |
| A2C (Advantage Actor-Critic) | Learns both value function and policy, Uses advantage for stability. | Atari Games, Open AI Gym, Temperature and Inventory control. |
| A3C (Asynchronous Advantage Actor-Critic) | Parallel training of multiple agents to stabilize learning. | Real-time video game. |
| DDPG (Deep Deterministic Policy Gradient) | For continuous action spaces. Combines Actor-Critic with deterministic policies. | Autonomous vehicles, Simulation, Car racing, Robotics |
| PPO (Proximal Policy Optimization) | Balances learning speed and stability; widely Used in real-world RL. | Open AI’s Robotic Agent, Trading Bots |
| TD3 (Twin Delayed DDPG) | Improves DDPG by reducing overestimation bias. | Continuous control tasks |
| SAC (Soft Actor-Critic) | Adds entropy to encourage exploration. | Robotics, complex simulations |
| TRPO (Trust Region Policy Optimization) | Policy optimization with constraints. | Robotic arms, Drones |
Deep Learning Algorithms (Subset of ML) – Use neural networks with multiple layers to learn complex patterns. The structured breakdown of key deep learning algorithms, categorized by their architecture and Application are given below:
| Algorithm | Description | Application |
| Standard Convolutional Neural Networks (CNN) | Uses convolutional layers for spatial feature extraction. | Object detection, image classification |
| Specialised Convolutional Neural Networks (CNN) | U-Net YOLO (You Only Look Once) R-CNN (Real-time object detection). StyleGAN (Image generation). | Medical image, Video analysis, Semantic and Instance Segmentation Object detection |
| Recurrent Neural Networks (RNNs) | Sequence data like time series. | Speech recognition, stock price prediction |
| LSTM (Long Short-Term Memory) | Type of RNN. Remember information for long periods with noisy or irregular data. | Forecasting weather temperature, Generate music |
| Bidirectional RNN | Processes sequences forward and backward. | Time series forecasting, NLP |
| GRU (Gated Recurrent Unit) | Type of RNN. Simplified version of LSTM, faster and easier. | NLP, Sentiment analysis, cryptocurrency |
| Feedforward Neural Networks SLP | Simple network where data flows in one direction-from input to output. | Predicting house prices, email spam detection. |
| Feedforward Neural Networks-MLP | Multilayer Perceptron . Multiple dense layers of fully connected neural network. | Tabular Data, Time Series prediction |
| BERT (Bidirectional Encoder Representations from Transformers) | Pre-trained for NLP tasks. | NLP, Question Answering |
| Vision Transformer (ViT) | Applies transformers to images. | ChatGPT |
| GPT (Generative Pre-trained Transformer) | Autoregressive text generation. | Chatbot, ChatGPT |
| Denoising Autoencoder | Dimensionality reduction, denoising, unsupervised learning | Anomaly detection, Image compression, Data visualization |
| Standard Autoencoder | Compresses input into a latent space. | Data denoising |
| Variational Autoencoder (VAE) | Generates new data through probabilistic approach. | Drug discovery, Molecular design |
| Basic Generative Adversarial Networks (GAN) | Data generation (images, music, video) | Deep fake, Art synthesis |
| DCGAN (Deep Convolutional GAN | Generator produces fake images. Discriminator tries to correctly classify real vs fake. | High quality image |
| CycleGAN | Image-to-image translation. Uses 2 Generators and 2 Discriminators. | Data augmentation, Horse to Zebra |
| StyleGAN | High-resolution face generation | Face editing & morphing |
| Deep Belief Networks (DBN) | Stacked layers of Restricted Boltzmann Machines (RBMs) | Face recognition, Disease prediction, Network intrusion |
| Self-Organizing Maps (SOM) | Projects high-dimensional data into 2D for visualization. | Clustering, Visualization |
| Graph Neural Networks (GNN) | Processes graph-structured data. | Social network analysis, molecule design. |
| Capsule Networks | Improves spatial hierarchy awareness in images. | Medical imaging, 3D Object Recognition |
| Neural Turing Machines (NTM) | Adds external memory to neural networks. | Question Answering and Reasoning |
When to Use Which Model?
- For linear relationships → Linear/Logistic Regression.
- For interpretability → Decision Trees, Logistic Regression.
- For high accuracy → Random Forest, Gradient Boosting (XGBoost).
- For small datasets → SVM, k-NN.
- For large datasets → Neural Networks, LightGBM.
- For grouping similar data → K-Means, DBSCAN, Hierarchical Clustering.
- For visualizing high-dimensional data → PCA, t-SNE, UMAP.
- For finding item associations → Apriori, FP-Growth.
- For detecting outliers → Isolation Forest, One-Class SVM.
- For discrete actions → Q-Learning, DQN.
- For continuous actions → PPO, SAC, TRPO.
- For sample efficiency → Model-Based (Dyna-Q, MCTS).
- For imitation learning → Inverse RL (GAIL).
- For image data → CNNs, Vision Transformers.
- For sequential data (Text/Time Series) → RNNs, LSTMs, Transformers.
- For generative tasks → GANs, VAEs.
- For reinforcement learning → DQN, PPO, SAC.
- For unsupervised learning → Autoencoders.
Key Characteristics of LLMs
- Massive Scale
- Trained on billions to trillions of text tokens (e.g., books, articles, code).
- Have hundreds of billions to trillions of parameters (e.g., GPT-4, Claude 3, Gemini).
- Transformer-Based Architecture
- Use self-attention mechanisms to process long-range dependencies in text.
- Examples: GPT (Generative Pre-trained Transformer), BERT, LLaMA, Mistral.
- Pre-Training & Fine-Tuning
- Pre-trained on general text data (unsupervised learning).
- Fine-tuned for specific tasks (e.g., chatbots, coding assistants).
- General-Purpose AI
- Can perform multiple NLP tasks without task-specific architectures.
How Do LLMs Work?
- Tokenization
- Input text is split into tokens (words/subwords).
- Example: “ChatGPT” → [“Chat”, “G”, “PT”].
- Embedding Layer
- Converts tokens into numerical vectors (embeddings).
- Transformer Layers
- Self-attention weighs the importance of different words.
- Feedforward networks process the data through multiple layers.
- Output Generation
- Predicts the next word (autoregressive models like GPT).
- Can also classify text (BERT).
Benefits of LLM
The benefits offered by LLMs encompass various aspects:
- Efficiency: LLMs automate tasks that involve the analysis of data, reducing the need for manual intervention and speeding up processes.
- Scalability: These models can be scaled to handle large volumes of data, making them adaptable to a wide range of applications.
- Performance: New-age LLMs are known for their exceptional performance, characterized by the capability to produce swift, low-latency responses.
- Customization flexibility: LLMs offer a robust foundation that can be tailored to meet specific use cases. Through additional training and fine-tuning, enterprises can customize these models to precisely align with their unique requirements and objectives.
- Multilingual support: LLMs can work with multiple languages, fostering global communication and information access.
- Improved user experience: They enhance user interactions with chatbots, virtual assistants, and search engines, providing more meaningful and context-aware responses.
- Multilingual support: LLMs are compatible with several languages, which improves access to information and communication around the world.
- Research and Innovation: LLMs have sparked research and innovation in ML and NLP which has benefited numerous fields and industries.
- Legal and Compliance: Reviewing documents, analyzing contracts, and keeping tabs on compliance are all areas where LLM models are being used. They make sure everything is in order legally, cut down on the time it takes to analyse documents, and stay in compliance with regulations.
Challenges & Limitations of LLM
While LLMs offer remarkable capabilities, they have their own set of limitations and challenges:
1. Hallucinations. Generating false & misleading information. Mistakes in code generation or analysis can yield software defects and issues.
2. Bias & Fairness Issues if the Model is trained on biased data.
3. Extremely high operational and computational cost because it is quite expensive to train, run and maintain the whole process.
4. Privacy Concerns. Many a times uses personal and sensitive data. Needs to protect user information and maintain confidentiality.
5. Glitch tokens. The use of maliciously designed prompts, referred to as glitch tokens, has the potential to disrupt the functionality of LLMs, highlighting the importance of robust security measures in LLM deployment.
6. Limited Reasoning Skills. Struggles with Complex Reasoning.
7. Lack of Long-Term Memory. Unable to retain information across different sessions for very long term.
8. Ethical Implications. AI can be misused by wrong actors. They can generate harmful and inappropriate content, raising ethical and content moderation concerns.
9. Absence of Cognitive Models: Unlike humans, who use cognitive models to reason through problems, make decisions, and plan, LLMs don’t have such mechanisms. They cannot adapt their responses in real-time based on an evolving understanding of a situation. Instead, they generate outputs based on patterns from past data.
Most Popular LLMs (2025) Latest
- OpenAI: GPT-4.5, GPT-4 o, o3, o4-mini, Codex mini
- DeepSeek: R1,V3
- Alibaba: Qwen 2.5-Max
- xAI: Grok 3
- Anthropic: Claude 3.7 Sonnet, Claude Opus 4
- Google: Gemini 2.5 Pro, Gemma 2, BERT
- Meta: LLaMA 3.3
- Mixtral AI: Mixtral Small 3, Large 2
- Eleuther AI: GPT NeoX
- Cohere: Command R+
- TII: Falcon 2
- LMSYS: Vicuna-13B
- Amazon: Nova
- Microsoft: Phi 4
Future of AI, ML, NLP and LLMs
Recent reports indicate that the global LLM market could grow from USD 6.4 billion in 2024 to over USD 36.1 billion by 2030 – a compound annual growth rate (CAGR) of more than 33%. North America alone is forecasted to hit astonishing numbers, with some estimates predicting the market could reach over USD 105 billion by 2030.
Goldman Sachs has suggested that generative AI could boost global GDP by as much as 7% over the next decade. Furthermore, the proliferation of AI-powered uses is expected to create new job categories while simultaneously automating routine tasks – an effect that has been compared to past technological revolutions like the advent of personal computing and mobile internet.
NLP a branch of AI is also witnessing a massive interest as the global NLP market was valued at USD 27.73 billion in 2022 and is expected to expand at a compound annual growth rate (CAGR) of 40.4% from 2023 to 2030. As AI is becoming a household name, more and more people are looking for AI-driven no-code platforms that will help them leverage this cutting-edge technology to boost their business growth without investing hundreds of thousands of productive man-hours.
Efficiency and Sustainability will be the Next Frontier
Creating smaller but more efficient LLMs with low cost like DeepSeek will be the real test. Today’s LLMs are consuming tremendous amounts of energy and require vast computational resources. Creating Green AI in future will be the goal.
Specialization and Customization with Domain-Specific LLMs
As industries mature in their adoption of AI, there will be a growing demand for LLMs that are tailored to domain-specific LLMs. These models can be fine-tuned with proprietary data to improve accuracy, compliance, and efficiency in tasks ranging from financial forecasting and fraud detection to personalized healthcare diagnostics.
Cross-Language and Cross-Domain Translation
The ability to work seamlessly across multiple languages and domains, breaking down barriers in global communication. This capability will be particularly transformative for MNCs and global research collaborations where real-time, accurate translation is paramount.
Bias Mitigation and Fairness
Tech leaders are exploring advanced techniques such as fairness-aware training, enhanced data curation, and continuous monitoring of deployed models. Organizations like OWASP are now providing updated “Top 10 Risks” for LLMs to help developers secure their systems against vulnerabilities and biases.
Data Privacy, Security, and Transparency
In a world increasingly concerned with privacy, LLMs must operate within strict data protection frameworks. Data privacy and security are critical components of AI development. Research is underway to develop explainable AI (XAI) techniques that allow users to understand the reasoning behind an LLM’s output- a crucial step in building trust and ensuring regulatory compliance.
Autonomous Agents
Perhaps one of the most exciting trends for 2025 is the rise of autonomous agents. These are AI-powered systems that can perform complex tasks- such as making purchases, scheduling meetings or even handling customer support – without constant human intervention.
Artificial General Intelligence (AGI)
AGI could be achieved in the coming few years – ushering in an era where machines not only assist but also enhance human decision-making at an unprecedented scale.
Few-Shot and Zero-Shot Learning
Recent advances in few-shot and zero-shot learning have drastically reduced the need of vast datasets and significant computational power for training LLM. Now, models can generalize from very few examples, enabling faster deployment and more agile updates. This is particularly important for businesses that need to rapidly adapt to changing market conditions without incurring massive retraining costs.
Democratization of AI
Perhaps the most promising trend is the democratization of AI. With the development of smaller, more efficient models and the proliferation of open-source projects, cutting-edge AI technology will become accessible to a much broader range of Users. This democratization is likely to spur innovation across industries and empower smaller companies and individual developers to create AI Uses that were once the exclusive domain of tech giants.
Comparison: CPU, GPU, TPU, NPU, DPU, QPU
| Feature | CPU | GPU | TPU | NPU | DPU | QPU |
| Acronym | Central Processing Unit | Graphics Processing Unit | Tensor Processing Unit developed by Google | Neural Processing Unit | Data Processing Unit | Quantum Processing Unit |
| Foundation Base | Classical Physics | Classical Physics | Classical Physics | Classical Physics | Classical Physics | Quantum Physics |
| Feature | General purpose sequential processing | Graphics and parallel processing | Matrix multiplication for Deep Learning | Designed to execute neural network operations | managing network security, and storage functions | Processes information in solid state superconducting qubits |
| Basis | Uses bits that are either 0 or 1 | Uses bits that are either 0 or 1 | Uses bits that are either 0 or 1 | Uses bits that are either 0 or 1 | Uses bits that are either 0 or 1 | Uses qubits that can be 0 & 1 or superposition of both 0 and 1. |
| Dependency | Uses electricity switched in transistors | Uses electricity switched in transistors | Uses electricity switched in transistors | Uses electricity switched in transistors | Uses electricity switched in transistors | Uses states of subatomic particles like electrons and photons. |
| Cores | Few (2-64) | Thousands | AI optimised chip | AI optimised chip | Many cores | Qubits |
| Clock Speed | High (3-5) GHz | Moderate (1-2 GHz) | Moderate | Moderate | Moderate | Extremely High |
| Parallelism | Limited | High | Very High | Moderate | High | Extremely High |
| Flexibility | Very High | High | Limited-Tensor flow based | Low | Data Centric | NA |
| Energy Efficiency | Low | Moderate | High | Very High | High | Low |
| Use Cases | General Tasks | AI training, gaming | Tensor flow AI Tasks | On Device AI IOT | Large Data Centres | Climate Forecasting, Drug Discovery |
Most Prominent Manufacturers of Processing Units
CPU Manufacturers: Intel, AMD, IBM, Apple, Qualcomm, ARM.
GPU Manufacturers: NVIDIA, AMD, Intel, ARM, Imagination Technologies.
TPU Manufacturer: Google, Coral (owned by Google), HAILO.
NPU Manufacturer: HAILO, Samsung, Qualcomm, Apple, Huawei.
DPU Manufacturer: Marvel, AMD, Microsoft, Intel, Nvidia.
QPU Manufacturer: IBM, Google, Intel, Microsoft, Nvidia, Alibaba, Baidu, Atom Computing, QpiAI